《深度探索 C++对象模型》(Inside The C++ Object Model)读书笔记
带*标题为重点章节的笔记。
第 1 章 关于对象(Object Lessons)
1.1 C++对象模型(The C++ Object Model)
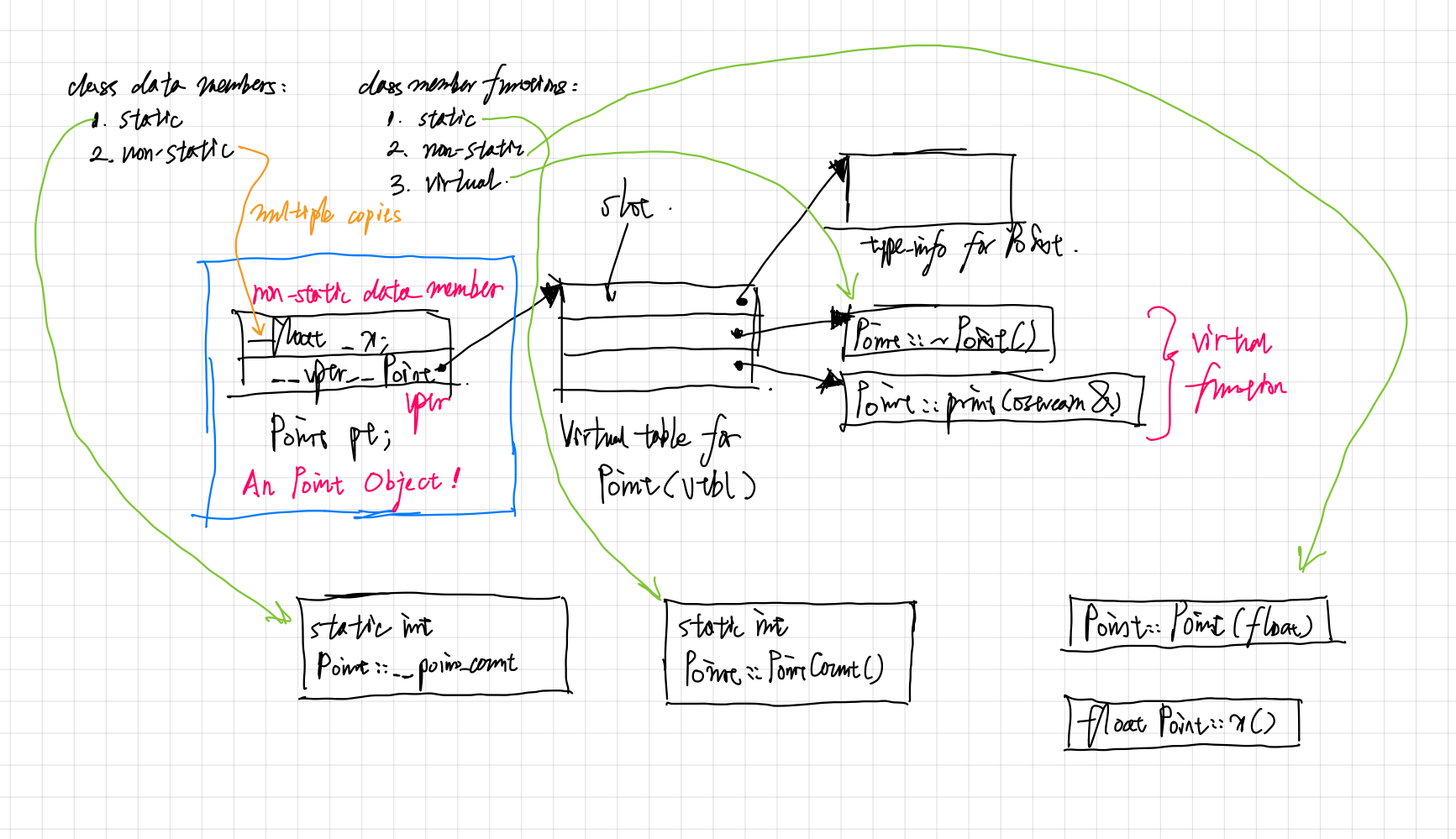
在 C++中,有两种 class data members:
- static data members,存储在 class object 之外。
- non-static data members,存储在每个 object 中。
和三种 class member functions:
- static member functions,不与任何 object 相关联。
- non-static member functions,与 object 相关联。
- virtual member functions,与 object 相关联。
C++对象模型通过两个步骤支持 virtual functions:
- 每一个 class 产生出一堆指向 virtual functions 的指针,放在表格之中。这个表格被称为 virtual table(vtbl)。
- 每一个 class object 都被安插一个指针,指向相关的 virtual table。通常这个指针被称为vptr。vptr 的设定(setting)和重置(resetting)都由每一个 class 的 constructor、destructor 和 copy assignment 运算符自动完成。每一个 class 所关联的type_info object(用以支持 runtime type identification,RTTI)也经由 virtual table 被指出来,通常放在表格的第一个 slot。
1.2 关键词所带来的差异(A Keyword Distinction)
策略性正确的 struct(The Politically Correct Struct)
C++中,处于相同 access control 区域中的数据,必定以其声明顺序出现在内存布局当中。然而,对于被放置在多个 access control 区域中的各个数据,其在内存布局中的顺序是不确定的。
C struct 在 C++中的一个合理用处是,当你要传递“一个复杂的 class object 的全部或者部分”到某个 C 函数去时,struct 声明可以将数据封装起来,并保证用于与 C 兼容的空间布局。
1.3 对象的差异
多态的主要用途经由一个共同的接口来影响类型的封装,实现当类型有所增加、删除和修改时,我们的代码无需改变。
多态是通过基类的指针或者基类的引用来使用的。
需要多少内存才能够表现一个 class object?一般而言有:
- 其 non-static data members 的总和大小。
- 加上任何由于 alignment 的需求而填补上去的空间(可能存在与 members 之间,也可能存在于集合体的边界)。
- 加上为了支持 virtual 而由内部产生的任何额外负担。
指针的类型
一个指向 ZooAnimal 的指针是如何地与一个指向 int 的指针或者指向 template Array 的指针不同的呢?从内存角度来看,其实这三者没有什么不同!其不同不在指针类型的不同、不在指向内容的不同(都是一个地址,通常为一个 word,在 64 位机器上是 8-bytes),而是在其所寻址出来的 object 的类型不同。也就是说,“指针类型”会教导编译器如何解释某个特定地址中的内存内容及其大小!
因此,转换(cast)其实是一种编译器指令。大部分情况下它不会改变一个指针所含的真正地址,它只影响“被指出之内存的大小和其内容”的解释方式。
加上多态之后
指向一个 derived class object 的指针或者引用和指向一个 base class object 的指针或者引用都指向 base class object 的起始地址,差别是指向 derived class object 的指针或者引用所涵盖的地址包含整个 derived class object,而指向 base class object 的指针或者引用只包含 base class object 的部分。
第 2 章 构造函数语意学(The Semantics of Constructors)
2.1 Default Constructor 的构造操作
A default constructor is a constructor which can be called with no arguments. https://en.cppreference.com/w/cpp/language/default_constructor
默认构造函数只会在编译器需要的时候被合成出来(为了编译通过),如果一个 class 没有任何用户定义的构造函数,那么就会有一个默认构造函数被隐式(implicitly)声明出来……一个被隐式声明出来的默认构造函数将是一个 trivial(平凡的)的构造函数,例如:
class Point {
public:
int x;
int y;
};
Point p; // 默认构造函数被调用
std::cout << p.x << std::endl;
上述代码片段的输出是什么呢?不会是 0,合成的默认构造函数只会满足编译器的要求,不对程序的行为做任何保证。这个是后面第五章提到Plain Ol’ Data。那么什么时候编译器会合成 non-trivial 的默认构造函数呢?
“带有 Default Constructor”的 Member Class Object
如果一个 class 没有任何 constructor,但它内含一个 member object,而后者有 default constructor,那么这个 class 的 implicit default constructor 就是“nontrivial”,编译器需要为该 class 合成出一个 default constructor。不过这个合成操作只有在 constructor 真正需要被调用时才会发生。两种情况:
- 合成的 default constructor 会调用 member object 的 default constructor。注意,被合成的 default constructor 只满足编译器的需要,而不是程序的需要,下面例子中 Bar1 的 default constructor 并没有初始化 val,所以输出的是一个随机值。
- 如果已存在 user-defined constructor,那么编译器不会合成 default constructor,而是会扩张已存在的 constructors,在其中安插一些代码,使得 user code 在被执行之前,先调用必要的 member object 的 default constructor。
class Foo {
public:
Foo() : c('a') { std::cout << "Foo constructor" << std::endl; }
private:
char c;
};
class Bar1 {
private:
int val;
Foo f;
};
class Bar2 {
public:
Bar2() : val(0) { std::cout << "Bar2 constructor" << std::endl; }
private:
int val;
Foo f;
};
Bar1 b1; // output: Foo constructor
std::cout << b1.val << std::endl; // output: random value.
Bar2 b2; // output: Foo constructor
// Bar2 constructor
“带有 Default Constructor”的 Base Class
这个很好理解,面向对象程序设计的基础。简单总结一下:
- 如果一个 class 没有任何 constructor,但它继承自一个带有 default constructor 的 base class,那么这个 class 的 implicit default constructor 就是“nontrivial”,编译器需要为该 class 合成出一个 default constructor。
- 如果设计者提供了多个 constructors,但其中都没有 default constructor,那么编译器不会合成 default constructor,而是会扩张已存在的 constructors,在其中安插一些代码,使得 user code 在被执行之前,先调用必要的 base class 的 default constructor。
- 如果同时存在着“带有 default constructors”的 member class objects,那些 member class objects 的 default constructors 会在 base class 的 default constructor之后被调用。
“带有一个 Virtual Function”的 Class
有两种情况:
- class 声明(或继承)一个 virtual function。
- class 派生自一个继承串链,其中有一个或更多的 virtual base classes。
原因是 vtbl 和 vptr,在构造派生对象的时候,必须为每一个派生类对象设定 vptr 的初值,设置为适当的 virtual table 的地址。所以编译器会合成一个 default constructor 或者为已存在的每一个 constructor 安插适当的代码,来完成这个任务。
“带有一个 Virtual Base Class”的 Class
和上面一个差不多。但是不同的地方在于,如果派生对象要访问基类对象中的数据成员,那么编译器会为每一个派生类对象设定一个指向 virtual base class 的指针,指向适当的 virtual base class subobject。这个指针的设定和重置都由每一个 class 的 constructor、destructor 和 copy assignment 运算符自动完成。
注意,在合成的 non-trivial default constructor 中,只有 base class subobjects 和 member class objects 会被初始化。所以其它的 non-static data member 都不会被初始化。
所以,常见的两种说法:
- 任何 class 如何没有定义 default constructor,编译器都会合成一个 default constructor。错!只有在编译器需要的时候(上述 4 种情况)才会合成一个 default constructor,剩下的所谓 implicit trivial default constructor 并不会被合成出来,也不会被调用。
- 编译器合成出来的 default constructor 会显示设定“class 内每一个 data member 的默认值”。错!编译器合成出来的 default constructor 只会显示设定 base class subobjects 和 member class objects 的默认值。
2.2 Copy Constructor 的构造操作
在 C++中,当以一个 object 的内容作为另一个 object 的初值时,copy constructor 会被调用。这种情况有很多,主要有三种:
- 初始化。
- 传递给函数。
- 从函数返回。
如果用户定义了 copy constructor,那么编译器就不会合成一个 default copy constructor。如果没有,那么编译器会合成一个 default copy constructor,这个 default copy constructor 会对 object 中的每个 non-static data member 进行 default memberwise initialization,即复制每一个 non-static data member 的值,但是它并不会复制其中的 member class object,而是以递归的方式对其施行 memberwise initialization。
和 default constructor 一样,C++ Standard 也把 copy constructor 分为 trivial 和 non-trivial,只有 non-trival 的 copy constructor 才会被合成出来、被调用。
那么怎样的 copy constructor 是 trivial 的呢?关键就在于其是否展现了 bitwise copy semantics。如果展现了,就是 trivial,如果不展现,就不是。所谓 bitwise copy semantics,就是指可以通过简单地复制内存中地每一个位(bit)来创建一个对象的副本,这种复制是不考虑对象内部结构和数据成员含义的,只是简单地复制内存中的位。
有 4 种情况,一个 class 不展现 bitwise copy semantics:
- 当 class 内含一个 member object 而后者的 class 声明有一个 copy constructor 时(不论是被 class 设计者显式地声明,就像前面的 String 那样;或是被编译器合成,像 class Word 那样)。
- 当 class 继承自一个 base class 而后者存在一个 copy constructor 时(再次强调,不论是被显式声明或是被合成而得)。
- 当 class 声明了一个或多个 virtual functions 时。
- 当 class 派生自一个继承串链,其中有一个或多个 virtual base classes 时。
很好理解,和 default constructor 很像。其中 3 是因为 vptr 和 vtbl 的存在,需要在构造派生对象的时候,为每一个派生类对象设定 vptr 的初值,设置为适当的 virtual table 的地址。所以编译器会合成一个 copy constructor 或者为已存在的每一个 constructor 安插适当的代码,来完成这个任务。而 4 则是因为 virtual base class 的存在,需要为每一个派生类对象设定一个指向 virtual base class 的指针,指向适当的 virtual base class subobject。
总而言之,当 class 复制操作不再保持 bitwise copy semantics,且未定义 copy constructor,则会被视为 non-trivial 的。
比如
std::vector就是 non-trivial 的,因为含有复制构造函数,所以编译器会合成一个 non-trivial 的复制构造函数。
2.3 程序转化语意学(Program Transformation Semantics)
显式的初始化操作(Explicit Initialization)
调用 copy constructor。
参数的初始化(Argument Initialization)
返回值的初始化(Return Value Initialization)
在使用者层面做优化(Optimization at the User Level)
在编译器层面做优化(Optimization at the Compiler Level)
NRV(Named Return Value):编译器会尝试避免不必要的拷贝构建,直接把返回值建构在其应该的位置上。比拷贝构建更加优化。
X bar() {
X xx;
// ... process xx
return xx;fd03bf43f0414473dcb0b54d3ad57283845c9fa1
}
void bar(X &__result ) {
// default constructor invoked
__result.X::X();
// ... process __result
return;
}
2.4 成员们的初始化队伍(Member Initialization List)
我们知道,初始化 data member 一般有两个机会,constructor 里面,或者在 member initialization list 里面。那么这两者有什么区别呢?大学学习的时候看过,背面经的时候也学习过,工作时间久了,才发现自己已经忘记这么做的具体原因是什么了。
在 constructor 里面初始化,编译器会先产生一个临时对象,然后将它初始化,之后用一个 assignment 运算符将临时的 object 指定给成员数据成员,然后在销毁临时对象。而在 member initialization list 里面初始化,编译器扩充之后的构造函数就会直接调用 member object 的 constructor,相当于直接从参数进行复制,而不是先产生一个临时对象,然后再用 assignment 运算符。
另外,扩充之后的构造函数中的变量初始化顺序,不是由 initialization list 的顺序决定的,而是由变量声明的顺序决定的。所以,如果一个变量的初始化依赖于另一个变量的初始化,那么就要注意变量的声明顺序。
第 3 章 Data 语意学(The Semantics of Data)
3.1 Data Member 的绑定(The Binding of a Data member)
较早版本的 C++有一个问题,在评估一个变量的时候,会将其立即绑定到一个地址上,这样就会导致一些问题。比如:
extern int a;
class MyClass {
public:
// 评估a,将其绑定到已解析的地址extern int a上,错误。
int A() const { return a; }
private:
int a; // 其实应该是这个!
}; // 现在,对a的求值延迟到这里。
后来这个问题被解决了,一个 inline 函数实体,在整个 class 声明未被完全看见之前,是不会评估求值的(member rewriting rule)。
3.2 Data Member 的布局(Data Member Layout)
三点:
- 同一个 access section 中的 non-static data members 的布局顺序是由它们在 class 声明中的次序决定的。
- 不同 access section 的 non-static data members 的布局顺序是不确定的,但各家的编译器基本上都是把一个以上的 access sections 连锁在一起,然后再按照次序排列。
- 编译器内部也可能会合成一些内部使用的 data members,比如 members 之间的边界调整啊(alignment),virtual table pointer 啊(vptr)等等。
3.3 Data Member 的存取
Static Data Members
会被转化为对该唯一 extern 实例的直接参考(?reference)操作,零成本。另外,若对一个 static data member 取地址,会得到一个指向其数据类型的指针(即非&Point3d::chunkSzie,因其本质是 int const *),而不是一个指向其 class member 的指针,因为 static member 并不内含在一个 class object 之中,而是在程序的 data segment 之中。
此外,static data member 的存取许可(public、protected 或 private),以及其本身与 class 的关联,并不会造成额外的负担。
有疑问的一句话:
且尽管 static data member 某种程度上可以被视为 global 变量,但是其只在 class 生命周期那可见。
一个可能的理解:
虽然静态数据成员在编译时被提出类定义之外(即在内存布局中,它们不会出现在类对象的内存布局中),但它们仍然保持了一定级别的类作用域封装。
Non-static Data Members
- 存取一个**class object(不是指针)**里面的 non-static data member,其效率和存取一个 C struct member 或者一个 non-derived class 的 member 是一样的。因为编译期就可以知道偏移量。
- 存取一个指向 class object 的指针里面的、继承自 virtual base class 的 non-static data member,会多出一个间接寻址的操作。因为在编译的时候,我们不知道这个指针必然指向哪一种 class type,因此也就不知道偏移量,所以这个操作必须延迟到执行期,经由一个额外的简介导引,才能解决。
*3.4 “继承”与 Data Member
考虑现在已经有了一个 2D 的坐标点的抽象数据结构,现在要扩展为 3D 的坐标点,怎么实现呢?一瞬间可能会有两个答案,现在不妨仔细讨论下这个问题。首先来最简单的。
只要继承不要多态(Inheritance without Polymorphism)
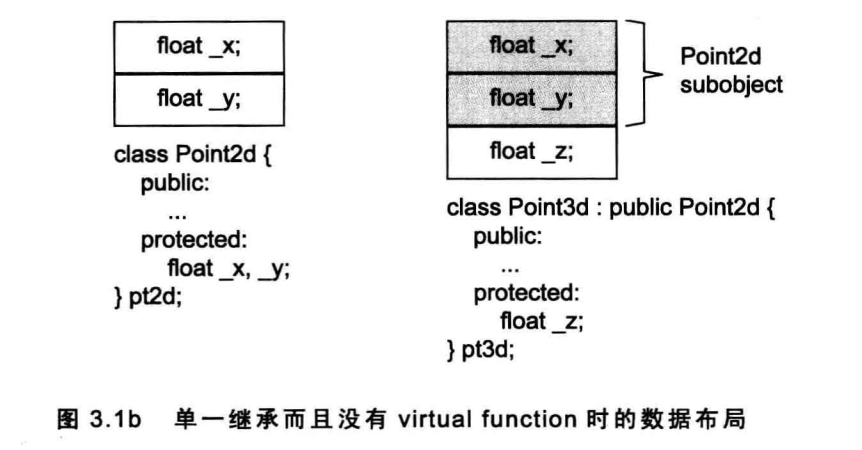
注意,这种情况下,Point3d 中不会含有 vptr,因为没有 virtual function。
注意要避免为了继承而继承,因为C++会保证“base class subobject 在 derived class 中的原样性”,所以若无法避免,会导致到对象的膨胀。
C++不会将 derived class 中的数据与 base class 中的数据合并,否则在复制的时候会产生 bug。试想 derived class 中的数据成员被安排到了 base class 中的 padding,那么将一个 base class object 复制给一个 derived class object 时,derived class object 中的数据成员就会 base class 的 padding 覆盖,从而产生 bug。
加上多态(Adding Polymorphism)
好处是可以统一接口,但是会导致对象的膨胀,因为每一个对象都要有一个 vptr,指向一个 virtual table,virtual table 中存放着 virtual function 的地址以及 type_info object 的地址。
单一继承下的内存布局:
多重继承(Multiple Inheritance)
和普通继承区别不大,多重继承的问题主要发生在 derived class objects 和其第二或者后继的 base class objects 之间的转换。有多态的的话,考虑 vptr 就行了。
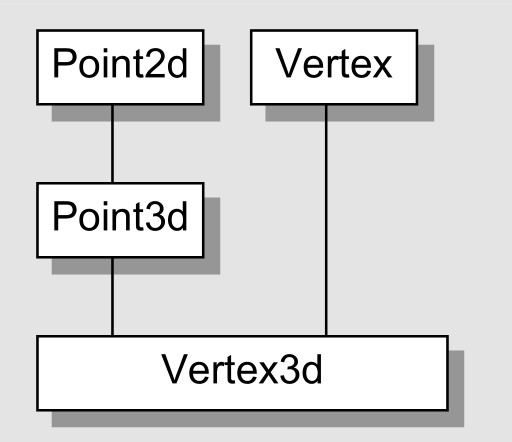
待办事项:画本例子中的内存布局。
对于一个多重派生的对象,将其地址指定给“最左端的 base class 的指针”,情况将和单一继承时相同,因为二者都指向相同的起始地址。至于第二个或者后继的 base class 的地址制定操作,则需要将地址修改过来,这个操作由编译器完成,加上或者减去介于中间的 base class subobjects 的大小。下面的讨论也是基于这个前提。
Vertex3d v3d;
Vertex *pv;
Point2d *p2d;
Point3d *p3d;
// pv是一个引用
pv = &v3d
// 编译器实际产生的代码
pv = (Vertex*)(((char *)&v3d) + sizeof(Point3d));
// 所以将v3d的地址指定给pv,实际上是将v3d的地址加上Point3d的大小,然后再转换为Vertex*。
地址低处 +-----------------+ // v3d, pv3d, p2d, p3d 指向这里
| Point3d 部分 | <- 基于Point2d
+-----------------+ // pv指向这里
| Vertex 部分 |
+-----------------+
| Vertex3d 部分 |<- 附加信息
地址高处 +-----------------+
其他情况也是类似的,只是注意,如果指针的话,实际转换的代码还需要判断指针是否为 NULL。至于引用,则不需要针对可能的 0 值做判断,因为引用不可能参考到“无物”(no object)。
// pv是一个指针。
Vertex *pv = &v3d;
// 编译器实际产生的代码。
Vertex *pv = pv ? (Vertex *)((char *)pv + sizeof(Point3d)) : 0;
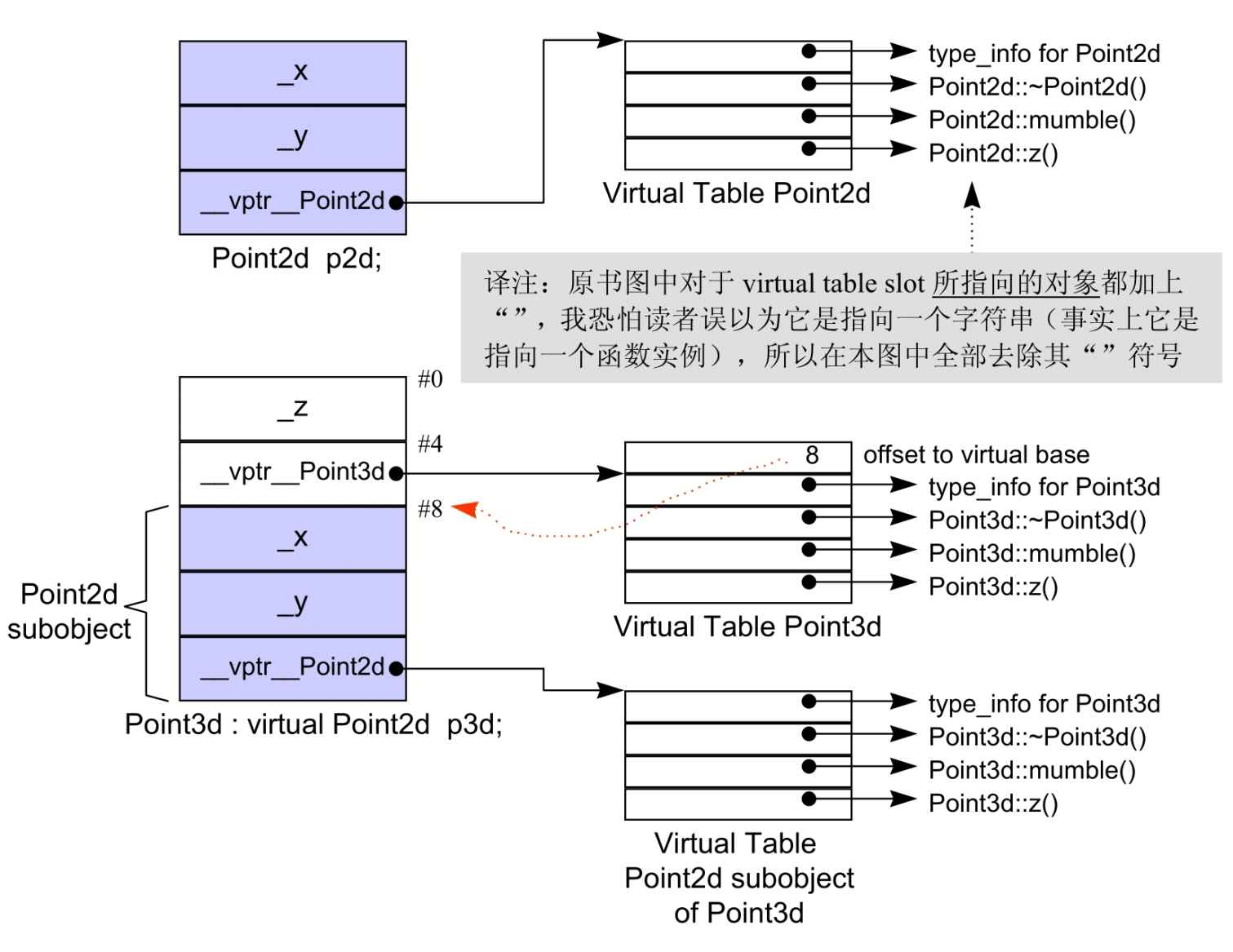
虚拟继承(Virtual Inheritance)
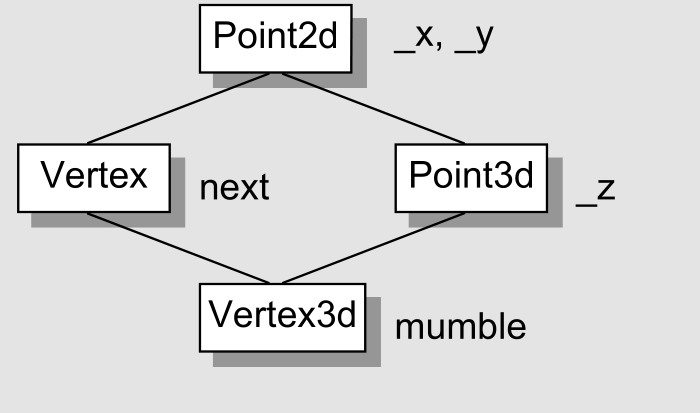
虚拟继承需要解决的问题是 shared subobject 继承的问题,即一个 derived class object(Vertex3d)中的多个 base class subobjects(Vertex 和 Point3d)共享一个 virtual base class subobject(Point2d)。Vertex 和 Point3d 之于 Vertex3d 是 base class,不是 virtual base class。
具体来说就是,虚拟继承需要将原来 Vectex 和 Point3d 各自维护的 Point2d,折叠成为一个由 Vertex3d 维护的单一的 Point2d object,只保留一个。同时还要保存 base class 和 derived class 的指针(以及引用)之间的多态指定操作。
因此可以这么说,对于中间的 Vertex 和 Point3d 而言,采用虚拟继承,将导致原来在多重继承中维护的 Point2d 的 subobject 发生变化(从各自拥有一个变成共享一个)。因此,可以将 Vertex 和 Point3d 分割为两个部分:一个共享区域和一个不变区域。共享区域就是存储会因每次派生继承操作而变化的数据,采用间接存取的方式,例如继承的部分;不变区域就是存储不会因每次派生继承操作而变化的数据,总是拥有固定的 offset,采用直接存取的方式,例如自己的数据成员。
各家编译器实现技术之间的差异就在于间接存取的方法不同,有三种主流策略。以下面的代码为例:
void Point3d::operator+=(Point const &rhs) {
_x += rhs._x;
_y += rhs._y;
_z += rhs._z;
}
在 cfront 策略下,这个运算符会被内部转化为:
void Point3d::operator+=(Point const &rhs) {
__vbcPoint2d->_x += rhs.__vbcPoint2d->_x; // Point2d为共享部分,通过指针间接存取
__vbcPoint2d->_y += rhs.__vbcPoint2d->_y; // vbc意为virtual base class
_z += rhs._z;
}
而一个 derived class 和一个 base class 的实例之间的转换,像这样:
Point2d *p2d = pv3d;
在 cfront 的实验模型之下,会变成:
// pv3d间接存取了共享的Point2d部分,不是通过offset直接存取。
// 对比上面多重继承中的最后一个例子。
Point2d *p2d = pv3d ? pv3d->__vbcPoint2d : 0;
当然缺点也很明显:1. 每一个对象要为其每一个 virtual base class 背负一个额外的指针;2. 每一个 virtual base class 的指针都要经过一个间接寻址的操作。
对于第二个问题,可以使用 Pointer Strategy 来解决,即通过拷贝将所有 nested virtual base class 的指针,放到 derived class object 中,这样就没有了多次间接寻址的操作。但是这样会导致对象的膨胀,因为每一个 derived class object 都要拷贝一份 virtual base class 的指针。这是该策略产生的数据布局:
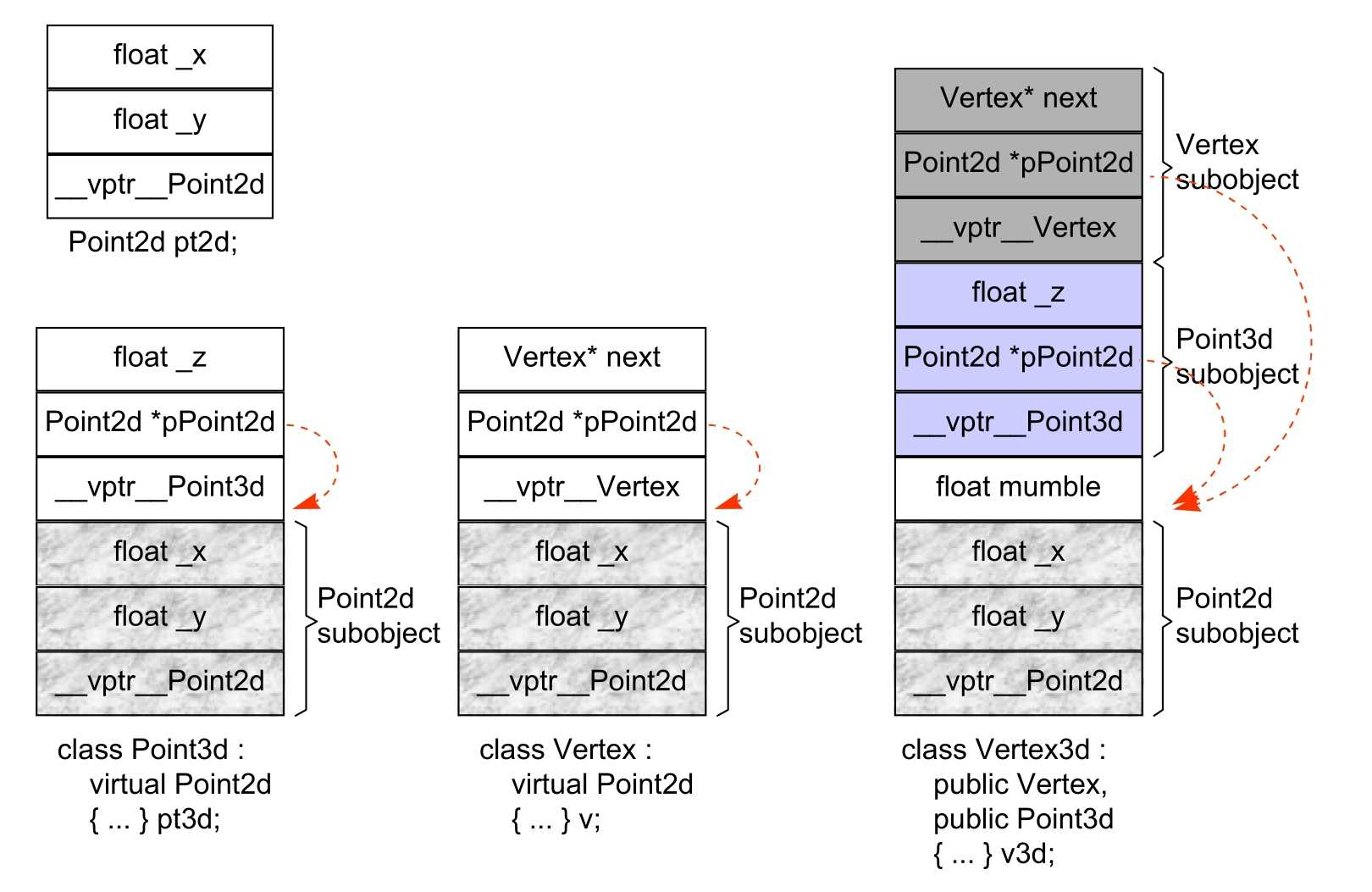
注意,上图中 base class subobject 在 derived subobject 的上面,而不是在下面,这是因为 derived class object 的地址是指向 base class subobject 的地址,而 virtual base class subobject 在 derived class object 的下面,通过一次间接寻址就可以找到。
对于第一个问题,有两个解决方案:1. 使用 virtual base class table;2. 在 virtual function table 中放置 virtual base class 的 offset,一表多用。
说实话,看到这里,前两章的内容我基本都忘了,太 trivial 了,唯一记住的就是 NRV,第三章的内容面试的时候应该会较为有用。
3.5 对象成员的效率(Object Member Efficiency)
越抽象、越继承,效率越低。正确的废话。
3.6 指向 Data Members 的指针(Pointer to Data Member)
一个有点神秘但颇有用处的语言特性,特别是如果你需要详细调查 class m embers 的底层布局的话。
“指向 Members 的指针”的效率问题
第 4 章 Function 语意学(The Semantics of Funtion)
4.1 Member 的各种调用方式
Nonstatic Member Function(非静态成员函数)
Nonstatic Member Function 相比 Nonmember function 有相同的效率,编译器会将其转换为一个普通的函数,只是多了一个 this 指针,指向调用该函数的对象,编译器会将 this 指针作为一个隐式参数传递给函数。怎么转换的呢?以Point3d Point3d::magitude()为例:
- 改函数签名,参数列表中加入 this 指针,
- 如果 non-const nonstatic member:
Point3d Point3d::magitude(Point3d * const this)。 - 如果是 const nonstatic member:
Point3d Point3d::magitude(const Point3d * const this)。
- 如果 non-const nonstatic member:
- 修改函数中 nonstatic data member 的使用,改为 this->data_member。
- 修改函数名称,通过 mangling 技术,将函数名改为
extern magnitude_7Point3dFv(register Point3d * const this)。之后,其调用从obj.magnitude();变成了magnitude__7Point3dFv(&obj)。 NRV 的优化也会实施,函数变成void magnitude_7Point3dFv(register Point3d * const this, register Point3d * const __result)。
名称的特殊处理(Name Mangling)
Name Mangling 是一种编译器技术,用于处理函数重载。C++支持函数重载,但是 C 语言不支持,所以 C++编译器需要将函数名进行特殊处理,以便区分不同的函数。Name Mangling 的过程是将函数名转换为一个唯一的字符串,这个字符串包含了函数的参数类型、返回值类型等信息。
*Virtual Member Functions(虚拟函数成员)
变成(*this->vptr[1])(this);。另外,如果在一个虚函数里面又调用了虚函数,按照之前的思路,这个调用会被编译器转换为register folat mag = (*this->vptr[2])(this);,但是,对于嵌套的虚函数调用,其已经被起初的虚拟机制处理过了(编译器已经知道 this 的类型了),所以显示地调用该函数实例会更加高效,因此会压制虚拟机制,实际会变成这样register float mag = Point3d::magnitude();。
Static Member Functions(静态成员函数)
*4.2 Virtual Member Functions(虚拟成员函数)
在 C++中,多态(polymorphism)表示“以一个 public base class 的指针(或 reference),寻址出一个 derived class object”的意思。例如下面的声明: Point *ptr; 我们可以指定 ptr 以寻址出一个 Point2d 对象: ptr = new Point2d; 或者是一个 Point3d 对象: ptr = new Point3d;
指针 ptr 扮演了一个输送机制的角色,通过 ptr 实现的多态表现为两个方面:
- 消极的多态,在编译期即可完成。通过 ptr,可以在程序的任何地方使用一组 derived class 类型的对象,而不需要知道这些对象的确切类型。
- 积极的多态,当对象被真正使用时,通过 ptr,可以调用 derived class 对象的成员函数。
为何不将判断类型需要的信息在编译期就确定下来呢?这样就不需要在运行期进行判断了。原因是:
- 如果放在对象当中,则会与兼容 C struct 冲突,C Struct 中没有 virtual function,加上额外的信息将使 C struct 膨胀并且打破链接兼容性。
- 如果放在指针当中,则会导致指针的膨胀,因为每一个指针都要带上额外的信息。
所以后来引入了 runtime type identification(RTTI),就能在执行期查询一个多态的 pointer 或者多态的 reference 了。
而 C++中多态又是通过虚拟函数来实现的,因此问题被区分出来,就是我们需要额外的运行时信息,用来鉴定哪些 classes 展现多态特性。这个问题很简单,识别一个 class 是否支持多态,唯一适当的方法就是看它是否有任何 virtual function,若有,则这个 class 就支持多态。
那么,什么样的额外信息需要被存储起来呢?
- ptr 所指对象的真实类型。这可以使我们选择正确的实例。实现上,可以用一个字符串或者数字,表示 class 的类型。
- 虚拟函数实例的位置,以便能够调用它。实现上,可以使用一个指针,指向一个表格,表格中持有程序的 virtual functions 的执行期地址。
由于这些信息是固定不变的,执行期不可能新增或者替换,所以其构建和存取皆可以由编译器完全掌控。在编译期,编译器执行两个步骤,完成上述信息的构建:
- 为了找到该表格,每一个 class object 被安插了一个由编译器内部产生的指针,指向该表格。
- 为了找到函数地址,每一个 virtual function 被指派了一个表格索引值。
而在执行期要做的,只是在特定的 virtual table slot(记录着 virtual function 的地址)中,激活 virtual function。
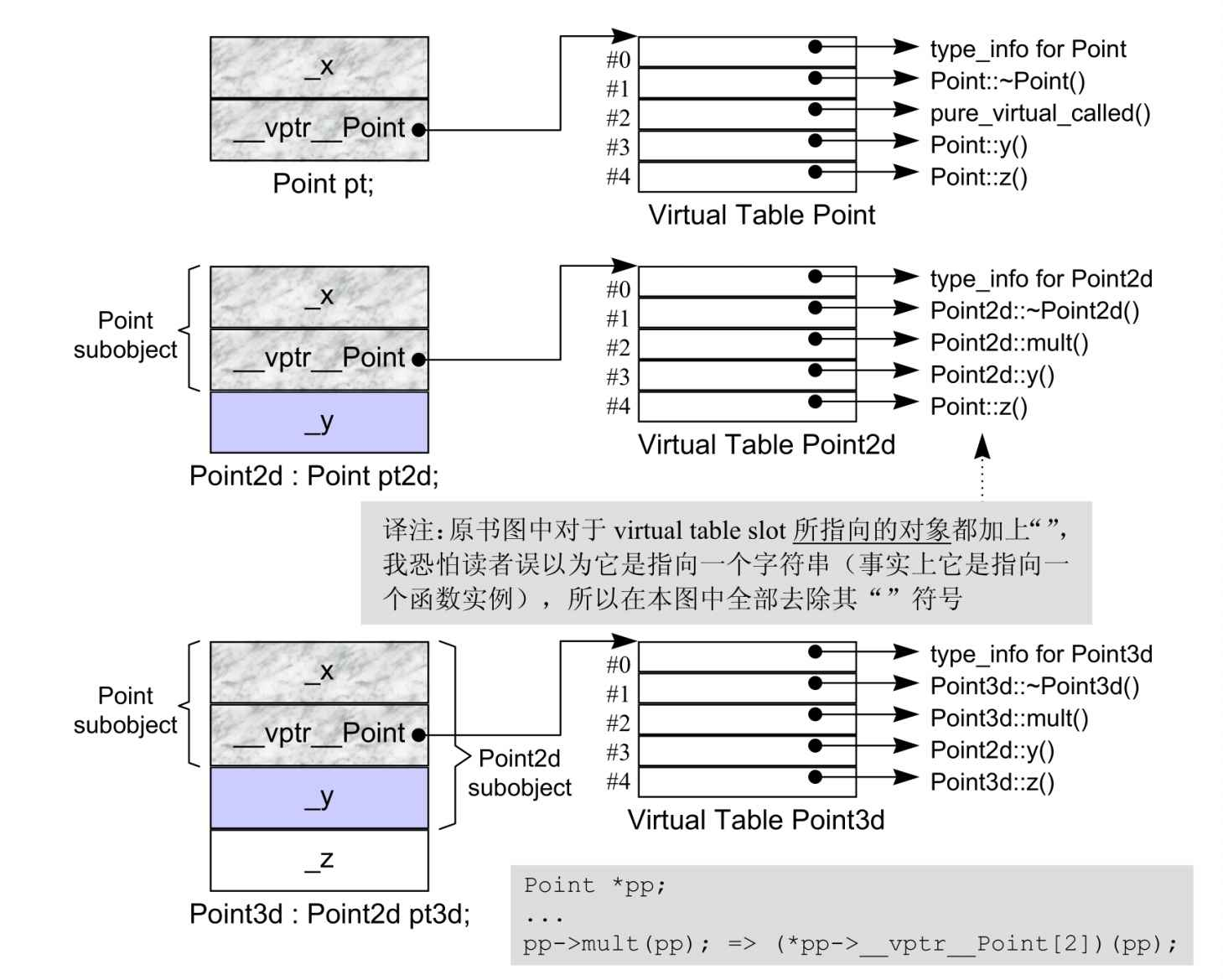
注:mult()是纯虚函数,所以 Point 的 vtbl 中没有其对应的地址,只有一个pure_virtul_called()作为占位符。
ptr->z();
// 实际编译器产生的代码。
(*ptr->vptr[4])(ptr);
这也是为什么实际上我们并不知道 ptr 的真实类型,但是我们可以通过 ptr 调用其成员函数的原因。
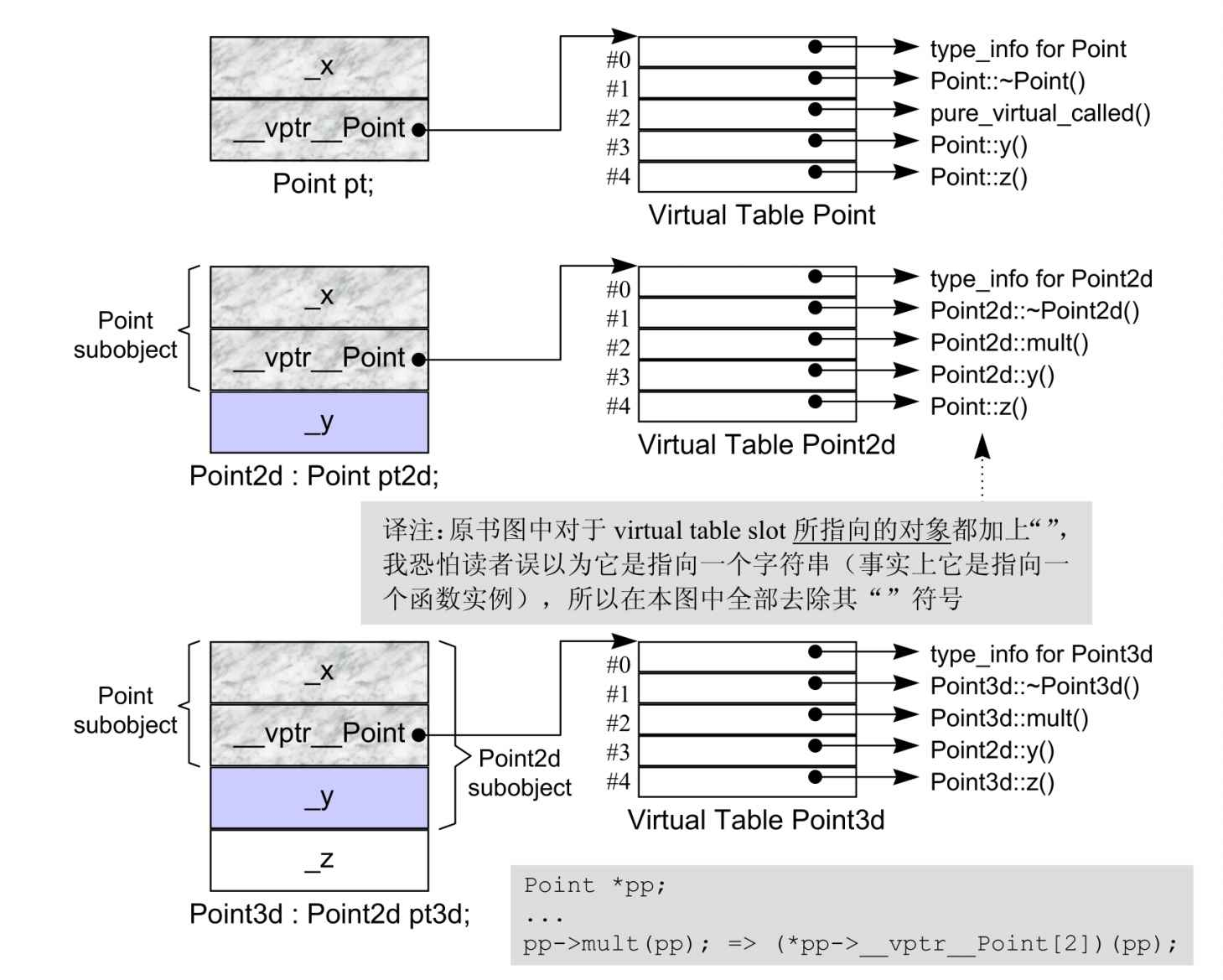
多重继承下的 Virtual Functions
记住理解这张图就可以了。
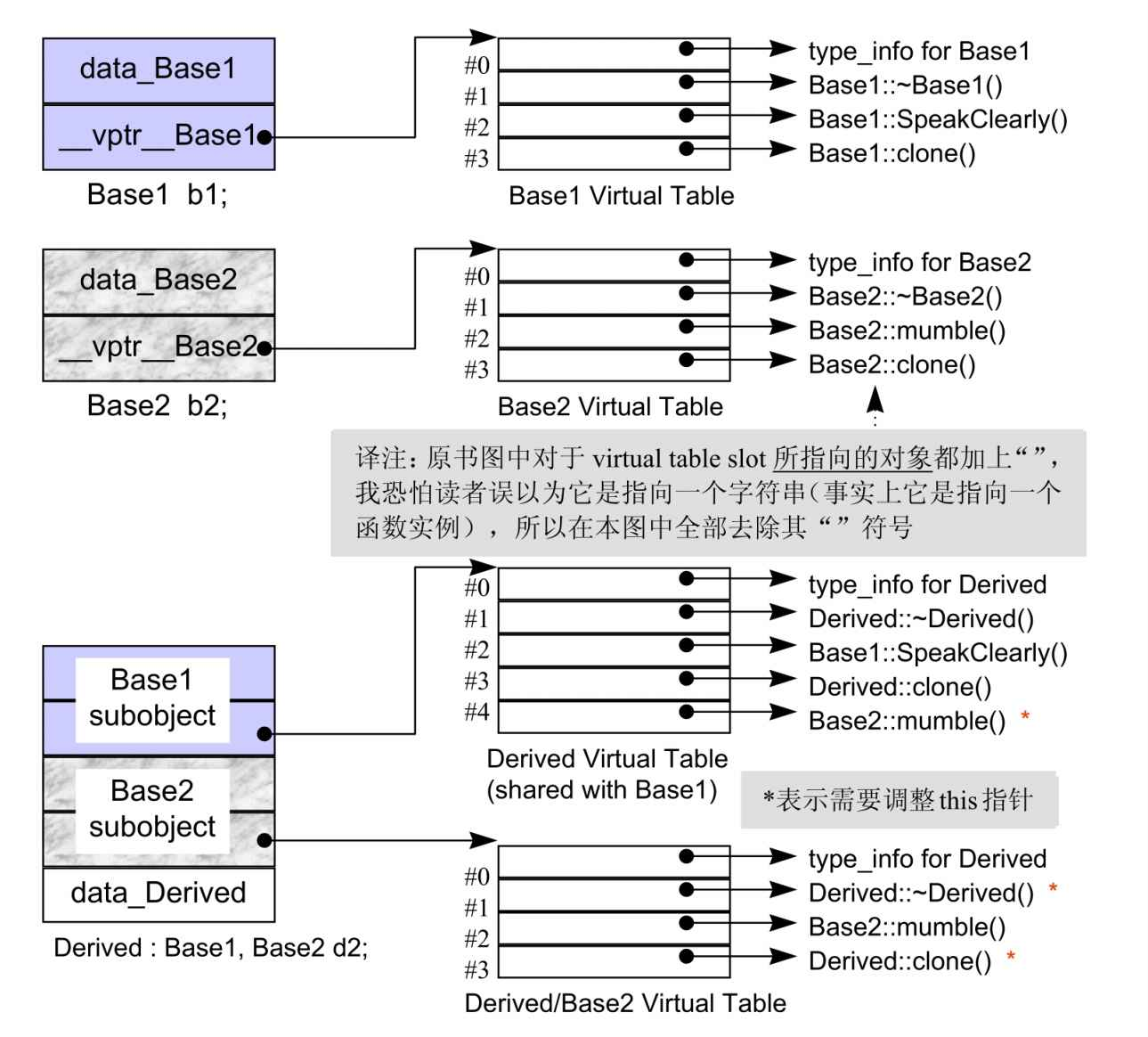
多重继承下有三个问题需要解决,以本例来说,分别是:(1)virutal destructor,(2)被继承下来的 Base2::memble(),(3)一组 clone()函数实例。
Virtual destructor
即通过第二或后继的 base class 指针,删除一个 derived class object。
Base2 *pbase2 = new Derived;
// 由第三章多重继承的讨论我们可以知道会发生下面的转换。
Derived *temp = new Derived;
Base2 *pbase2 = temp ? (Base2 *)((char *)temp + sizeof(Base1)) : 0;
// 可以直接对pbase2施以delete么?
delete pbase2;
此时,指针pbase2需要再次被调整,因为此时该指针指向 subobject Base2 地址开始的地方,但是我们需要指向整个 Derived object 的地址。所以,编译器会将delete pbase2;转换为delete (Derived *)((char *)pbase2 - sizeof(Base1));。然而,这个偏移量,在编译时期是无法确定的!因为 pbase2 所指的真正对象只有在执行期才能确定下来。怎么办呢?
- 扩容 virtual table,使它容纳此处所需要的 this 指针。每一个 virtual table slot,不再只是一个指针,而是一个集合体,内含可能的 offset 以及地址,于是析构操作变成了
(*pbase2->vptr[1].faddr)(pbase2 + pbase2->vptr[1].offset);。这么做的缺点也很明显。 - Thunk 技术,所谓 thunk 就是一小段汇编代码,用来调整 this 指针。这么做有个缺点,需要调整 this 指针的类型,其虚表对应的 slot 指向的是 thunk 代码,不需要调整的,指向的是析构函数。
Base1 *pbase1 = new Derived;
Base2 *pbase2 = new Derived;
delete pbase1; // Base1的virtual table slot对应slot指向其析构函数。
delete pbase2; // Base2的virtual table slot对应slot指向thunk地址。
所以,真正的做法是,在一个 derived class 内含 n-1 个额外的 virtual tables,n 表示上一层的 base classes 的个数。对于本例而言,会有两个 virtual tables 被编译器产生出来。
被继承下来的函数 mumble()
这个和上面的问题反过来了,是通过一个 derived class 的指针,调用从第二个 base class 中继承而来的 virtual function。在次情况下,derived class 指针需要再次调整,以指向第二个 base class subobject。
Derived *pd = new Derived;
pd->mumble();
// 实际编译器产生的代码。
pd = (Base2 *)((char *)pd + sizeof(Base1));
(*pd->vptr[2])(pd);
一组 clone()函数实例
Base2 *pb1 = new Derived;
// 调用的实际是Derived* Derived::clone()
// 返回值必须被修改,以指向Base2 subobject.
Base2 *pb2 = pb1->clone();
虚拟继承下的 Virtual Functions
4.3 函数的效能
越抽象、越继承,效率越低。正确的废话。
4.4 指向 Member Function 的指针 Pointer-to-Member Functions
无聊。
4.5 Inline Functions
如果把这些存取函数声明为 inline,我们就可以继续保持直接存取 members 的那种高效率——虽然我们亦兼顾了函数的封装性
真正的 inline 函数操作,是在调用的那一点上的。这会带来参数的求值操作以及临时性对象的管理问题。所以,inline 函数的效率并不是绝对的。
形式参数(Formal Arguments)
inline int min(int i, int j) {
return i < j ? i : j;
}
inline int bar() {
int minval;
int val1;
int val2;
minval = min(val1, val2); // 1
// 以上代码会被转换为
// minval = val1 < val2 ? val1 : val2;
minval = min(1024, 2048); // 2
// 以上代码会被转换为
// minval = 1024;
minval = min(foo(), bar() + 1); // 3
// 以上代码会被转换为
// int t1;
// int t2;
// minval = (t1 = foo()), (t2 = bar() + 1), t1 < t2 ? t1 : t2;
// 副作用,导入了一个临时对象,以避免重复求值。
return minval;
}
局部变量(Local Variables)
inline 函数中的局部变量,再加上有副作用的参数,可能会导致大量临时性对象的产生。
第 5 章 构造、析构、拷贝语意学(Semantics of Construction,Destruction,and Copy)
纯虚函数的存在(Presence of a Pure Virtual Function)
一个人竟然可以定义和调用(invoke)一个 pure virtual function;不过它只能被静态地调用(invoked statically,经有::),不能经由虚拟机制调用。
唯一的例外是 pure virtual destructor:class 设计者一定得定义它。为什么?因为每一个 derived class destructor 会被编译器加以扩张,以静态调用的方式调用其“每一个 virtual base class”以及“上一层 base class”的 destructor。因此,只要缺乏任何一个 basec lass destructors 的定义,就会导致链接失败。且为了实现这个功能,编译器不会压抑用户对于纯虚析构函数的调用。
所以较好的方式是,不要将析构函数声明为纯虚函数。
虚拟规格的存在(Presence of a Virtual Specification)
一般而言,把所有的成员函数都声明为 virtual function,然后再靠编译器的优化操作把非必要的 virtual function 去除,并不是一个好的设计理念。例如基类中的 getter、setter,它们常常为 inline,这些函数声明为虚函数,会增加负担。
虚拟规格中 const 的存在
可能基类中的虚函数不会修改 data member,但是派生类中重载的实现,可能会修改。酌情而定是否要将虚函数声明为 const 的。
重新考虑 class 的声明
结合上面的讨论,得到的较为适当的一种设计。
class AbstructBase{
public:
virtual ~AbstructBase(); // 不再是pure virual.
virtual void interface() = 0; // 不再是const.
const char* mumble() const { return _mumble; } // 不再是virtual.
protected:
AbstructBase(char *pc = 0); // 新增一个带唯一参数的构造函数。
char * _mumble;
};
5.1 “无继承”情况下的对象构造
如果是 Plain Ol’ Data,观念上,trival 的构造函数和析构函数都会被产生并且被调用,但是这些 trival 函数,不是没被定义,就是没被调用。
// Plain Ol' Data
class Point {
float x, y, z;
};
Point global; // 既没有被构造,也没有被析构。
Point foobar() {
Point local; // 没有被构造,也没有被析构。
Point *heap = new Point; // 没有default constructor被触发。
*heap = local; // 无non trival的assignment operator生成,bitwise的。
// ...stuff...
delete heap; // 并不会触发trival的destructor.
return local; // 观念上会触发trival copy constructor,但是Plain Ol' Data, 因此是bitwise的。
}
抽象数据结构(Abstract Data Type)
对于 Plain Ol’ Data,如果用户提供了 defualt constructor 或者 default destructor,则会被调用之。Default constructor 会在调用处被 inline expansion,即:
Point local;
local._x = 0.0; local._y = 0.0; local._z = 0.0;
编译器有一种优化机制来识别 inline constructor,如果构造函数执行 member-to-member 的常量指定操作,那么编译器会抽出这些值,并且对待它们就好像是 explicit initialization list 所供应的那样。
// explicit initialization list
Point local1 = {1.0, 1.0, 1.0};
为继承做准备
可以参考 2.1 和 2.2,这一小节是上述两个章节的补充。一般来说,这种情况下合成的 non trivial 函数,对 vptr 的设定操作,会被放置到函数的最开始处。
最好还是自己提供 default constructor 以及 copy constructor。
5.2 继承体系下的对象构造
单以继承和多重继承没什么需要注意的。
*vptr 初始化语意学(The Semantics of the vptr Initialization)
更一般性地说,在一个 class(本例为 Point3d)的 constructor(和 destructor)中,经由构造中的对象(本例为 PVertex 对象)来调用一个 virtual function,其函数实例应该是在此 class(本例为 Point3d )中有作用的那个。由于各个 constructors 的调用顺序,上述情况是必要的。
意思是,当每一个 PVertex base class constructors 被调用时,编译系统必须保证有适当的 size()(示例函数,用以输出继承体系中每一个 class 的大小)函数实例被调用。怎样才能办到这一点?
如果调用操作限制必须在 constructor(或 destructor)中直接调用,那么答案十分明显:将每一个调用操作以静态方式决议之,千万不要用到虚拟机制。如果是在 Point3d constructor 中,就显式调用 Point3d::size() 。
因此,vptr 的设定操作,在 base class constructors 调用操作之后,但是在程序员供应的代码或是“member initialization list 中所列的 members 初始化操作”之前。
这样,在本 subobject 的构造过程中,调用的 virtual function 实例,就能保证是在本 subobject 的 class 中有作用的那个。
后面的讨论怎么越来越复杂了,我现在都搞不清楚在一个层级继承的体系中,其 vptr 的位置所在了。算了,看个大概吧。
总结就是:
- 在 Derived class constructor 中,“所有 virtual base classes”及“上一层 base class”的 constructor 会被调用。
- 上述完成之后,对象的 vptr(s)被初始化,指向相关的 virtual table(s)。
- 如果有 member initialization list 的话,将在 constructor 体内拓展开来。这必须在 vptr 被设定之后才做,以免有一个 virtual member function 被调用。
- 最后,执行程序员提供的代码。
以下情况,vptr 必须被设定:
- 当一个完整的对象被构造起来时.如果我们声明一个 Point 对象,则 Point constructor 必须设定其 vptr。
- 当一个 subobject constructor 调用了一个 virtual function(不论是直接调用或间接调 用)时。
虚拟继承
显然,由多个 base class 继承而来的 virtual base class subobject,只会被构造一次。因此不能简单地将 derived class 的构造函数扩容,以调用其 base class 的构造函数。否则会导致 base class 的构造函数被调用多次。
一种解决方法是,在扩容的构造函数中,有条件地调用共享基类的构造函数。
5.5 *析构语意学(Semantics of Destruction)
一个程序员定义的 destructor 被扩展的方式类似 constructors,但顺序相反:
- destructor 的函数本体首先被执行。
- 如果 class 拥有 member class objects,而后者拥有 destructors,那么它们会以其声明顺序的相反顺序被调用。
- 如果 object 内含一个 vptr,那么首先重设(reset)相关的 virtual table。
- 如果有任何直接的(上一层)nonvirtual base class 拥有 destructor,它们会以其声明顺序的相反顺序被调用。
- 如果有任何 virtual base classes 拥有 destructor,而目前讨论的这个 class 是最尾端(most-derived)的 class,那么它们会以其原来的构造顺序的相反顺序被调用。
就像蜕皮一样,一个 PVertex 对象在归还其内存空间之前,会依次变成一个 Vertex3D 对象、一个 Vertex 对象、一个 Point3D 对象,最后会变成一个 Point 对象。当我们在 destructor 中调用 member functions 时,对象的蜕变会因为 vptr 的重新设定而受到影响。
关于为何要重新设置 vptr 的值,见“多重继承下的 Virtual Function”。